1. Internet & Web
There is a difference between the internet and the web (World Wide Web).
The internet is a worldwide system of interconnected networks and computers. It is the technological structure that makes the web possible.
The web is the system that allows for the sharing of documents and other media that have been stored on computers within this internet network.
The Internet
Most histories of the internet begin with the launch of the ARPANET project by the Defense Advanced Research Projects Agency (DARPA) in 1969. ARPANET was a network that linked university mainframe computers at UCLA, Stanford, UC-Santa Barbara, and the University of Utah. This network would eventually grow to several hundred locations and would provide the foundation for the modern day Internet.
But, of course, there were countless innovations prior to ARPANET that made this possible. If you are curious, look up information about computer time-sharing and other important concepts that led to the development of the internet.
There are two especially important innovations that ARPANET would utilize that made the modern internet possible: packet switching and TCP/IP.
Packet Switching
In a packet-switched network, data is broken into chunks (or packets) of a specific size with instructions included for its destination and how it is to be reassembled. Once it arrives at its destination, it is reassembled. When you send information over the internet, each packet may take a different route on the network to its destination.
The development of the packet-switched network was really important. Instead of a communication channel that simply goes directly from one point to another, there are now numerous paths that the data can take. If something goes wrong along the way, the packet can take a different route.
TCP/IP
The adoption of TCP/IP in 1983 is what truly ushered in the internet age.
TCP (Transmission Control Protocol) is the basic communication language that makes all of this data-transfer and communication between networked computers possible. It is responsible for verifying the correct delivery of data from sender to destination on the network.
IP (Internet Protocol) is responsible for moving packets of data from node to node on the network. It forwards the data based upon the IP address contained in the packet.
The IP address is a numeric identifier for devices on the network. When a packet is sent over the network, its destination is declared by the IP address provided.
For example, an IP address might look something like this: 172.64.35.9
Computers work best with numbers, but humans prefer words. The solution is to use IP addresses that correspond to domain names. So when you type a domain name into your browser (e.g., "40px.org"), the domain name is translated to a numeric IP address (e.g., "172.64.35.9") by a Domain Name Service (DNS) server.
The web address https://40px.org is also known as a URL (Uniform Resource Locator). More specifically, it is known as an absolute URL. For more information about URLs, see this page.
The Web
The World Wide Web is a system of interlinked documents that may be accessed via the internet. In 1989, Tim Berners-Lee wrote a proposal that would become the basis for the web.
Documents on the web are referred to as hypertext documents. Hypertext documents contain hyperlinks (references) to other documents.
This is the basic idea that the web is built upon: A bunch of documents that are linked to each other.
On the web, you can easily click a link and land at another document. All of these documents together form a network of inter-linked documents that make up the web.
A browser, such as Firefox or Chrome, is the communication tool used to translate this system of protocols, programming languages, and various other technical things into an easy-to-use window to the web.
Client-Server Relationship
While this is an oversimplification of the concept, we could say that these things are generally true:
- Your computer is a client machine.
- The computer that hosts a website is a server.
When you use Firefox to access a website, Firefox is a client application. It is a program on a client machine (your computer) that requires connecting to a server over a network to fulfill its primary purpose.
A client application requests information and expects a response from the server. Without a network connection to a server, Firefox has limited value.
In a restaurant, the server brings the food to you (the client). This might be a helpful way of understanding the concept and remembering it.

This communication that takes place between the client and server is made possible by TCP/IP.
Understanding the concept of clients and servers will become especially important when we touch on programming languages later in this course. Some programming languages run on the server (such as Python) and others run on the client side (like JavaScript).
Servers
Both servers and client machines have operating systems, such as Windows, Mac OS X, or Linux. Unix-based operating systems, such as Linux, are most often used for web servers. So, a server is a computer. It's a computer that has been configured to allow access to its resources over a network.
There are many types of servers, such as mail servers, file servers, media servers, game servers, and more. A server can host more than just websites. And the server might not even be connected to the internet. For example, the local network at your school or place of work might have a file server that allows multiple client machines on that network to connect.

When you visit 40px.org, you are interacting with a computer at a data center.
Directory Structure
Whether you use Windows or Mac, you are most likely familiar with the concept of folders. On a Unix-based operating system, like Linux, these are called directories.
Directories are simply folders, just like all of those on your laptop or desktop computer. If you can manage files and folders on your computer, you should have no problem doing the same when working on a web server.
The illustration below shows an example of a simple directory structure for a fictional website at recipes.com. On the web server, there is a directory that represents the "web root" for a domain. This means that documents placed into this directory can be accessed on the web when you go to to the website's address (domain) in a web browser. This directory is often named htdocs or public_html.
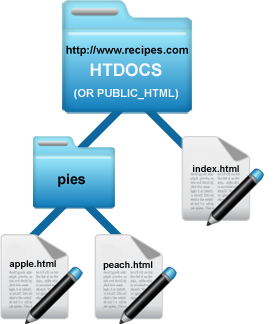
The server looks for a file with a certain name to serve as the "home page" for a directory. Often, this name is index.html. In our example above, we have an index.html file inside of the web root directory. So, this will be the home page for recipes.com and could be found with a browser at recipes.com/index.html, or simply at recipes.com
There is also a directory named pies inside of the web root. And within this directory, we have html files named apple.html and peach.html. These pages could be accessed in a web browser at recipes.com/pies/apple.html and recipes.com/pies/peach.html
As mentioned above, the server looks for a file named index to serve up as a home page. This is also true for directories within your web root directory. For example, if we placed an index.html file in the pies directory, it could be accessed in a browser at recipes.com/pies/